Module tsflex.processing
Processing module.
Processing guide
The following sections will explain the processing module in detail.
Jump to API reference
Working example ✅
tsflex is built to be intuitive, so we encourage you to copy-paste this code and toy with some parameters!
This executable example creates a processing pipeline that contains 3 processing steps (abs, median filter, and detreding, each applied on a different subset of series).
import pandas as pd; import scipy.signal as ss; import numpy as np
from tsflex.processing import SeriesProcessor, SeriesPipeline
# 1. -------- Get your time-indexed data --------
# Data contains 3 columns; ["ACC_x", "ACC_y", "ACC_z"]
url = "https://github.com/predict-idlab/tsflex/raw/main/examples/data/empatica/"
data = pd.read_parquet(url + "acc.parquet").set_index("timestamp")
# 2 -------- Construct your processing pipeline --------
processing_pipe = SeriesPipeline(
processors=[
SeriesProcessor(function=np.abs, series_names=["ACC_x", "ACC_y"]),
SeriesProcessor(ss.medfilt, ["ACC_y", "ACC_z"], kernel_size=5)
]
)
# -- 2.1. Append processing steps to your processing pipeline
processing_pipe.append(SeriesProcessor(ss.detrend, ["ACC_x", "ACC_z"]))
# 3 -------- Process the data --------
processing_pipe.process(data=data, return_df=True)
# which outputs:
| timestamp | ACC_x | ACC_y | ACC_z |
|---|---|---|---|
| 2017-06-13 14:22:13+02:00 | -32.8736 | 5.0000 | 51.1051 |
| 2017-06-13 14:22:13.031250+02:00 | -32.8737 | 5.0000 | 51.1051 |
| 2017-06-13 14:22:13.062500+02:00 | -32.8738 | 5.0000 | 51.105 |
| 2017-06-13 14:22:13.093750+02:00 | -32.8739 | 5.0000 | 51.105 |
| 2017-06-13 14:22:13.125000+02:00 | -32.8740 | 5.0000 | 51.1049 |
| … | … | … | … |
Tip
More advanced processing examples can be found in these example notebooks
Getting started 🚀
The processing functionality of tsflex is provided by a SeriesPipeline that contains SeriesProcessor steps. The processing steps are applied sequentially on the data that is passed to the processing pipeline.
Components
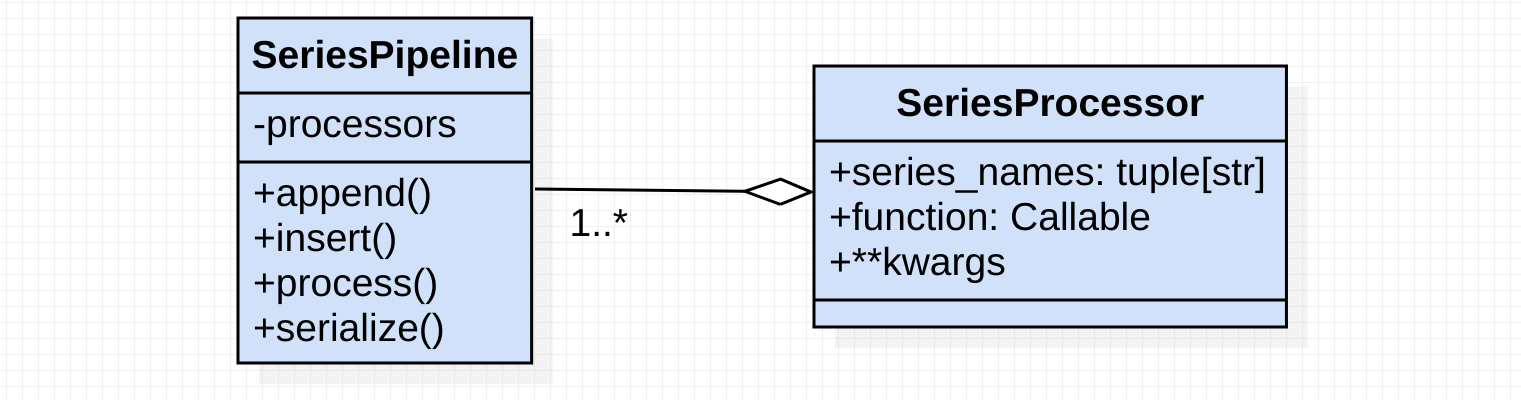
As shown above, there are 2 relevant classes for processing.
- SeriesPipeline: serves as a pipeline, withholding the to-be-applied processing steps
- SeriesProcessor: an instance of this class describes a processing step.
Processors are defined by:function: the Callable processing-function - e.g. scipy.signal.detrendseries_names: the name(s) of the series on which the processing function should be applied**kwargs: the keyword arguments for thefunction.
The snippet below shows how the SeriesPipeline & SeriesProcessor components work:
import numpy as np; import scipy.signal as ss
from tsflex.processing import SeriesProcessor, SeriesPipeline
# The SeriesPipeline takes a List[SeriesProcessor] as input
processing_pipe = SeriesPipeline(processors=[
SeriesProcessor(np.abs, ["series_a", "series_b"]),
SeriesProcessor(ss.medfilt, "series_b", kernel_size=5) # (with kwargs)
]
)
# We can still append processing steps after instantiating.
processing_pipe.append(processor=SeriesProcessor(ss.detrend, "series_a"))
# Apply the processing steps
processing_pipe.process(...)
Processing functions
The function that processes the series should match this prototype:
function(*series: pd.Series, **kwargs)
-> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]]
Hence, the processing function should take one (or multiple) series as input, these may be followed by some keyword arguments. The output of a processing function can be rather versatile.
Note
A function that processes a np.ndarray instead of pd.Series
should work just fine.
In this section you can find more info on advanced usage of processing functions.
Important notes 📢
In a SeriesPipeline it is common behavior that series are transformed (i.e., replaced).
Hence, it is important to keep the following principles in mind when:
- Applying processing functions that take 1 series as input will (generally) transform (i.e., replace) the input series .
- Countermeassure: this behavior does not occur when the processing function returns a
pd.Serieswith a different name.
- Countermeassure: this behavior does not occur when the processing function returns a
- The order of steps (
SeriesProcessors) in the processing pipeline (SeriesPipeline) might affect the output.
Advanced usage 👀
Versatile processing functions
As explained above tsflex is rather versatile in terms of function input and output.
tsflex does not just allow one-to-one processing functions, but also many-to-one, one-to-many, and many-to-many functions are supported in a convenient way:
-
many-to-one; the processing function should- take multiple series as input
- output a single array or (named!) series / dataframe with 1 column
Example
def abs_diff(s1: pd.Series, s2: pd.Series) -> pd.Series:
return pd.Series(np.abs(s1-s2), name=f"abs_diff_{s1.name}-{s2.name}")
-
one-to-many; the processing function should- take a single series as input
- output a list of (named!) series or a dataframe with multiple columns
Example
def abs_square(s1: pd.Series) -> List[pd.Series]:
s1_abs = pd.Series(np.abs(s1), name=f"abs_{s1.name}")
s1_square = pd.Series(np.square(s1), name=f"square_{s1.name}")
return [s1_abs, s1_square]
-
many-to-many; (combination of the above) the processing function should- take multiple series as input
- output a list of (named!) series or a dataframe with multiple columns
Example
def abs_square_diff(s1: pd.Series, s2: pd.Series) -> List[pd.Series]:
s_abs = pd.Series(np.abs(s1-s2), name=f"abs_{s1.name}-{s2.name}")
s_square = pd.Series(np.square(s1-s2), name=f"square_{s1.name}-{s2.name}")
return [s_abs, s_square]
DataFrame decorator
In some (rare) cases a processing function requires a pd.DataFrame as input.
For these cases we provide the dataframe_func decorator. This decorator wraps the processing function in the SeriesPipeline, provided a pd.DataFrame as input instead of multiple pd.Series.
Note
In most cases series arguments are sufficient; you can perform column-based operations on multiple pd.Series (e.g., subtract 2 series). Only when row-based operations are required (e.g., df.dropna(axis=0)), a pd.DataFrame is unavoidable.
Logging
When a logging_file_path is passed to the SeriesPipeline its process method, the execution times of the processing steps will be logged.
Expand source code
"""Processing module.
.. include:: ../../docs/pdoc_include/processing.md
"""
__author__ = "Jonas Van Der Donckt, Emiel Deprost, Jeroen Van Der Donckt"
from .. import __pdoc__
from .logger import get_processor_logs
from .series_pipeline import SeriesPipeline
from .series_processor import SeriesProcessor, dataframe_func
__pdoc__["SeriesProcessor.__call__"] = True
__all__ = [
"dataframe_func",
"SeriesProcessor",
"SeriesPipeline",
"get_processor_logs",
]API reference of tsflex.processing
.logger-
Contains the used variables and functions to provide logging functionality …
.series_pipeline-
SeriesPipeline class for time-series data (pre-)processing pipeline.
.series_processor-
Code for time-series data (pre-)processing.
.utils-
(Advanced) utilities for the processing pipelines.
Functions
def dataframe_func(func)-
Expand source code
def dataframe_func(func: Callable) -> Callable: """Decorate function to use a DataFrame instead of multiple series (as argument). This decorator can be used for functions that need to work on a whole `pd.DataFrame`. It will convert the required series into a DataFrame using an **outer merge**. The function's prototype should be: func(df : pd.DataFrame, **kwargs) -> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]] So the decorated `func` has to take a DataFrame as first argument. Notes ----- Only when you want to perform row-based operations, such as `df.dropna(axis=0)`, this wrapper is needed. Hence, in most cases that `func` requires a `pd.DataFrame`, series arguments would be sufficient; as you can perform column-based operations on multiple `pd.Series` (e.g., subtract 2 series) and most dataframe operations are also available for a `pd.Series`. """ def wrapper( # type: ignore[no-untyped-def] *series: pd.Series, **kwargs, ) -> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]]: series_dict = {s.name: s for s in series} df = series_dict_to_df(series_dict) res = func(df, **kwargs) return res wrapper.__name__ = "dataframe_func: " + func.__name__ return wrapperDecorate function to use a DataFrame instead of multiple series (as argument).
This decorator can be used for functions that need to work on a whole
pd.DataFrame. It will convert the required series into a DataFrame using an outer merge.The function's prototype should be:
func(df : pd.DataFrame, **kwargs) -> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]]So the decorated
funchas to take a DataFrame as first argument.Notes
Only when you want to perform row-based operations, such as
df.dropna(axis=0), this wrapper is needed. Hence, in most cases thatfuncrequires apd.DataFrame, series arguments would be sufficient; as you can perform column-based operations on multiplepd.Series(e.g., subtract 2 series) and most dataframe operations are also available for apd.Series. def get_processor_logs(logging_file_path)-
Expand source code
def get_processor_logs(logging_file_path: str) -> pd.DataFrame: """Get execution (time) info for each processor of a ``SeriesPipeline``. Parameters ---------- logging_file_path: str The file path where the logged messages are stored. This is the file path that is passed to the ``SeriesPipeline`` its ``process`` method. Returns ------- pd.DataFrame A DataFrame containing each processor its series names, output names, and (%) duration. """ df = _parse_logging_execution_to_df(logging_file_path) df["duration"] = pd.to_timedelta(df["duration"], unit="s") return dfGet execution (time) info for each processor of a
SeriesPipeline.Parameters
logging_file_path:str- The file path where the logged messages are stored. This is the file path that
is passed to the
SeriesPipelineitsprocessmethod.
Returns
pd.DataFrame- A DataFrame containing each processor its series names, output names, and (%) duration.
Classes
class SeriesProcessor (function, series_names, **kwargs)-
Expand source code
class SeriesProcessor(FrozenClass): """Class that executes a specific operation on the passed series_dict. Parameters ---------- function : Callable The function that processes the series (given in the `series_names`). The prototype of the function should match: \n function(*series: pd.Series, **kwargs) -> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]] .. note:: A function that processes a ``np.ndarray`` instead of ``pd.Series`` should work just fine. series_names : Union[str, Tuple[str, ...], List[str], List[Tuple[str, ...]]] The names of the series on which the processing function should be applied. This argument should match the `function` its input; \n * If `series_names` is a (list of) string (or tuple of a single string), than `function` should require just one series as input. * If `series_names` is a (list of) tuple of strings, than `function` should require `len(tuple)` series as input **and in exactly the same order**. A list means multiple series (combinations) to process; \n * If `series_names` is a string or a tuple of strings, than `function` will be called only once for the series of this argument. * If `series_names` is a list of either strings or tuple of strings, than `function` will be called for each entry of this list. .. note:: when passing a list as `series_names`, all items in this list should have the same type, i.e, either \n * all a `str` * or, all a `tuple` _with same length_. \n **kwargs: dict, optional Keyword arguments which will be also passed to the `function` Notes ----- If the output of `function` is a `np.ndarray` or a `pd.Series` without a name, than (items of) the given `series_names` must have length 1, i.e., the function requires just 1 series! That series its name and index are used to transform (i.e., **replace**) that series. If you want to transform (i.e., **replace**) the input series with the processor, than `function` should return either: \n * a `np.ndarray` (see above). * a `pd.Series` with no name or with the same name as the input series. * a `pd.DataFrame` with (one) column name equal to the input series its name. * a list of `pd.Series` in which (exact) one series has the same name as the input series. Series (& columns) with other (column) names will be added to the series dict. """ def __init__( # type: ignore[no-untyped-def] self, function: Callable, series_names: Union[str, Tuple[str, ...], List[str], List[Tuple[str, ...]]], **kwargs, ): series_names = [to_tuple(names) for names in to_list(series_names)] # Assert that function inputs (series) all have the same length assert all( len(series_names[0]) == len(series_name_tuple) for series_name_tuple in series_names ) self.series_names: List[Tuple[str, ...]] = series_names self.function = function self.name = self.function.__name__ self.kwargs = kwargs self._freeze() def get_required_series(self) -> List[str]: """Return all required series names for this processor. Return the list of series names that are required in order to execute the processing function. Returns ------- List[str] List of all the required series names. """ return list(set(flatten(name for name in self.series_names))) def __call__(self, series_dict: Dict[str, pd.Series]) -> Dict[str, pd.Series]: """**Call**culates the processed series. Parameters ---------- series_dict : Dict[str, pd.Series] A dict of `pd.Series` containing the data that need to be processed. The key should always be the accompanying series its name. Returns ------- Dict[str, pd.Series] The processed `series_dict`. Raises ------ KeyError Raised when a key is not present in the `series_dict` but required for the processing. TypeError Raised when the output of the `SeriesProcessor` is not of the correct type. Notes ----- * The `series_dict` is an internal representation of the time-series data . This internal representation is constructed in the `process` method of the `SeriesPipeline`. * If you want to test or debug your `SeriesProcessor` object, just encapsulate your instance of this class in a `SeriesPipeline`. The latter allows more versatile input for its `process` method. """ t_start = time.perf_counter() # Only selecting the series that are needed for this processing step # requested_dict = {} # try: # for sig in self.get_required_series(): # requested_dict[sig] = series_dict[sig] # except KeyError as key: # # Re raise error as we can't continue # raise KeyError( # "Key %s is not present in the input dict and needed for processor %s" # % (key, self.name) # ) # Variable that will contain the final output of this method processed_output: Dict[str, pd.Series] = {} def get_series_list(keys: Tuple[str, ...]) -> List[pd.Series]: """Get an ordered series list view for the given keys.""" return [series_dict[key] for key in keys] def get_series_dict(keys: Tuple[str, ...]) -> Dict[str, pd.Series]: """Get a series dict view for the given keys.""" return {key: series_dict[key] for key in keys} for series_name_tuple in self.series_names: func_output = self.function( *get_series_list(series_name_tuple), **self.kwargs ) func_output = _handle_seriesprocessor_func_output( func_output, get_series_dict(series_name_tuple), self.name, ) # Check that the output of the function call produces unique columns / keys assert ( len(set(processed_output.keys()).intersection(func_output.keys())) == 0 ) processed_output.update(func_output) elapsed = time.perf_counter() - t_start logger.info( f"Finished function [{self.name}] on {self.series_names} with output " f"{list(processed_output.keys())} in [{elapsed} seconds]!" ) return processed_output def __repr__(self) -> str: """Return formal representation of object.""" repr_str = self.name + (" " + str(self.kwargs)) repr_str += " : " + " ".join([str(s) for s in self.series_names]) return repr_str def __str__(self) -> str: """Return informal representation of object.""" return self.__repr__()Class that executes a specific operation on the passed series_dict.
Parameters
function:Callable-
The function that processes the series (given in the
series_names). The prototype of the function should match:function(*series: pd.Series, **kwargs) -> Union[np.ndarray, pd.Series, pd.DataFrame, List[pd.Series]]Note
A function that processes a
np.ndarrayinstead ofpd.Seriesshould work just fine. series_names:Union[str, Tuple[str, …], List[str], List[Tuple[str, …]]]-
The names of the series on which the processing function should be applied.
This argument should match the
functionits input;- If
series_namesis a (list of) string (or tuple of a single string), thanfunctionshould require just one series as input. - If
series_namesis a (list of) tuple of strings, thanfunctionshould requirelen(tuple)series as input and in exactly the same order.
A list means multiple series (combinations) to process;
- If
series_namesis a string or a tuple of strings, thanfunctionwill be called only once for the series of this argument. - If
series_namesis a list of either strings or tuple of strings, thanfunctionwill be called for each entry of this list.
Note
when passing a list as
series_names, all items in this list should have the same type, i.e, either- all a
str - or, all a
tuplewith same length.
- If
**kwargs:dict, optional- Keyword arguments which will be also passed to the
function
Notes
If the output of
functionis anp.ndarrayor apd.Serieswithout a name, than (items of) the givenseries_namesmust have length 1, i.e., the function requires just 1 series! That series its name and index are used to transform (i.e., replace) that series.If you want to transform (i.e., replace) the input series with the processor, than
functionshould return either:- a
np.ndarray(see above). - a
pd.Serieswith no name or with the same name as the input series. - a
pd.DataFramewith (one) column name equal to the input series its name. - a list of
pd.Seriesin which (exact) one series has the same name as the input series.
Series (& columns) with other (column) names will be added to the series dict.
Ancestors
- tsflex.utils.classes.FrozenClass
Methods
def get_required_series(self)-
Expand source code
def get_required_series(self) -> List[str]: """Return all required series names for this processor. Return the list of series names that are required in order to execute the processing function. Returns ------- List[str] List of all the required series names. """ return list(set(flatten(name for name in self.series_names)))Return all required series names for this processor.
Return the list of series names that are required in order to execute the processing function.
Returns
List[str]- List of all the required series names.
def __call__(self, series_dict)-
Expand source code
def __call__(self, series_dict: Dict[str, pd.Series]) -> Dict[str, pd.Series]: """**Call**culates the processed series. Parameters ---------- series_dict : Dict[str, pd.Series] A dict of `pd.Series` containing the data that need to be processed. The key should always be the accompanying series its name. Returns ------- Dict[str, pd.Series] The processed `series_dict`. Raises ------ KeyError Raised when a key is not present in the `series_dict` but required for the processing. TypeError Raised when the output of the `SeriesProcessor` is not of the correct type. Notes ----- * The `series_dict` is an internal representation of the time-series data . This internal representation is constructed in the `process` method of the `SeriesPipeline`. * If you want to test or debug your `SeriesProcessor` object, just encapsulate your instance of this class in a `SeriesPipeline`. The latter allows more versatile input for its `process` method. """ t_start = time.perf_counter() # Only selecting the series that are needed for this processing step # requested_dict = {} # try: # for sig in self.get_required_series(): # requested_dict[sig] = series_dict[sig] # except KeyError as key: # # Re raise error as we can't continue # raise KeyError( # "Key %s is not present in the input dict and needed for processor %s" # % (key, self.name) # ) # Variable that will contain the final output of this method processed_output: Dict[str, pd.Series] = {} def get_series_list(keys: Tuple[str, ...]) -> List[pd.Series]: """Get an ordered series list view for the given keys.""" return [series_dict[key] for key in keys] def get_series_dict(keys: Tuple[str, ...]) -> Dict[str, pd.Series]: """Get a series dict view for the given keys.""" return {key: series_dict[key] for key in keys} for series_name_tuple in self.series_names: func_output = self.function( *get_series_list(series_name_tuple), **self.kwargs ) func_output = _handle_seriesprocessor_func_output( func_output, get_series_dict(series_name_tuple), self.name, ) # Check that the output of the function call produces unique columns / keys assert ( len(set(processed_output.keys()).intersection(func_output.keys())) == 0 ) processed_output.update(func_output) elapsed = time.perf_counter() - t_start logger.info( f"Finished function [{self.name}] on {self.series_names} with output " f"{list(processed_output.keys())} in [{elapsed} seconds]!" ) return processed_outputCallculates the processed series.
Parameters
series_dict:Dict[str, pd.Series]- A dict of
pd.Seriescontaining the data that need to be processed. The key should always be the accompanying series its name.
Returns
Dict[str, pd.Series]- The processed
series_dict.
Raises
KeyError- Raised when a key is not present in the
series_dictbut required for the processing. TypeError- Raised when the output of the
SeriesProcessoris not of the correct type.
Notes
- The
series_dictis an internal representation of the time-series data . This internal representation is constructed in theprocessmethod of theSeriesPipeline. - If you want to test or debug your
SeriesProcessorobject, just encapsulate your instance of this class in aSeriesPipeline. The latter allows more versatile input for itsprocessmethod.
class SeriesPipeline (processors=None)-
Expand source code
class SeriesPipeline: """Pipeline for applying ``SeriesProcessor`` objects sequentially. Parameters ---------- processors : List[Union[SeriesProcessor, SeriesPipeline]], optional List of ``SeriesProcessor`` or ``SeriesPipeline`` instances that will be applied sequentially to the internal series dict, by default None. **The processing steps will be executed in the same order as passed in this list.** """ def __init__( self, processors: Optional[List[Union[SeriesProcessor, SeriesPipeline]]] = None ): self.processing_steps: List[SeriesProcessor] = [] # TODO: dit private of niet? if processors is not None: assert isinstance(processors, list) self.processing_steps = list( flatten( [ p.processing_steps if isinstance(p, SeriesPipeline) else [p] for p in processors ] ) ) def get_required_series(self) -> List[str]: """Return all required series names for this pipeline. Return the list of series names that are required in order to execute all the ``SeriesProcessor`` objects of this processing pipeline. Returns ------- List[str] List of all the required series names. """ return list( set(flatten(step.get_required_series() for step in self.processing_steps)) ) def append(self, processor: Union[SeriesProcessor, SeriesPipeline]) -> None: """Append a ``SeriesProcessor`` at the end of the pipeline. Parameters ---------- processor : Union[SeriesProcessor, SeriesPipeline] The ``SeriesProcessor`` or ``SeriesPipeline`` that will be added to the end of the pipeline. """ if isinstance(processor, SeriesProcessor): self.processing_steps.append(processor) elif isinstance(processor, SeriesPipeline): self.processing_steps.extend(processor.processing_steps) else: raise TypeError( "Can only append SeriesProcessor or SeriesPipeline, " + f"not {type(processor)}" ) def insert( self, idx: int, processor: Union[SeriesProcessor, SeriesPipeline] ) -> None: """Insert a ``SeriesProcessor`` at the given index in the pipeline. Parameters ---------- idx : int The index where the given processor should be inserted in the pipeline. Index 0 will insert the given processor at the front of the pipeline, and index ``len(pipeline)`` is equivalent to appending the processor. processor : Union[SeriesProcessor, SeriesPipeline] The ``SeriesProcessor`` or ``SeriesPipeline`` that will be inserted.<br> .. note:: If the given processor is a ``SeriesPipeline``, all its processors will be inserted sequentially, starting from the given index. """ if isinstance(processor, SeriesProcessor): self.processing_steps.insert(idx, processor) elif isinstance(processor, SeriesPipeline): for i, ps in enumerate(processor.processing_steps): self.insert(idx + i, ps) else: raise TypeError( "Can only insert a SeriesProcessor or SeriesPipeline, " + f"not {type(processor)}" ) def process( self, data: Union[pd.Series, pd.DataFrame, List[Union[pd.Series, pd.DataFrame]]], return_df: Optional[bool] = False, return_all_series: Optional[bool] = True, drop_keys: Optional[List[str]] = None, copy: Optional[bool] = False, logging_file_path: Optional[Union[str, Path]] = None, ) -> Union[List[pd.Series], pd.DataFrame]: """Execute all ``SeriesProcessor`` objects in pipeline sequentially. Apply all the processing steps on passed Series list or DataFrame and return the preprocessed Series list or DataFrame. Parameters ---------- data : Union[pd.Series, pd.DataFrame, List[Union[pd.Series, pd.DataFrame]]] Dataframe or Series or list thereof, with all the required data for the processing steps. \n **Remark**: each Series / DataFrame must have a ``pd.DatetimeIndex``. **Remark**: we assume that each name / column is unique. return_df : bool, optional Whether the output needs to be a series list or a DataFrame, by default False. If True the output series will be combined to a DataFrame with an outer merge. return_all_series : bool, optional Whether the output needs to return all the series, by default True. * If True the output will contain all series that were passed to this method. * If False the output will contain just the required series (see ``get_required_series``). drop_keys : List[str], optional Which keys should be dropped when returning the output, by default None. copy : bool, optional Whether the series in ``data`` should be copied, by default False. logging_file_path : Union[str, Path], optional The file path where the logged messages are stored, by default None. If ``None``, then no logging ``FileHandler`` will be used and the logging messages are only pushed to stdout. Otherwise, a logging ``FileHandler`` will write the logged messages to the given file path. Returns ------- Union[List[pd.Series], pd.DataFrame] The preprocessed series. Notes ----- * If a ``logging_file_path`` is provided, the execution (time) info can be retrieved by calling ``logger.get_processor_logs(logging_file_path)``. <br> Be aware that the ``logging_file_path`` gets cleared before the logger pushes logged messages. Hence, one should use a separate logging file for each constructed processing and feature instance with this library. * If a series processor its function output is a ``np.ndarray``, the input series dict (required dict for that function) must contain just 1 series! That series its name and index are used to return a series dict. When a user does not want a numpy array to replace its input series, it is his / her responsibility to create a new ``pd.Series`` (or ``pd.DataFrame``) of that numpy array with a different (column) name. * If ``func_output`` is a ``pd.Series``, keep in mind that the input series gets transformed (i.e., replaced) in the pipeline with the ``func_output`` when the series name is equal. Raises ------ _ProcessingError Error raised when a processing step fails. """ # Delete other logging handlers delete_logging_handlers(logger) # Add logging handler (if path provided) if logging_file_path: f_handler = add_logging_handler(logger, logging_file_path) # Convert the data to a series_dict series_dict: Dict[str, pd.Series] = {} for s in to_series_list(data): # Assert the assumptions we make! if len(s): assert isinstance(s.index, pd.DatetimeIndex) # TODO: also check monotonic increasing? if s.name in self.get_required_series(): series_dict[str(s.name)] = s.copy() if copy else s elif return_all_series: # If all the series have to be returned series_dict[str(s.name)] = s.copy() if copy else s output_keys: Set[str] = set() # Maintain set of output series for processor in self.processing_steps: try: processed_dict = processor(series_dict) output_keys.update(processed_dict.keys()) series_dict.update(processed_dict) except Exception as e: # Close the file handler (this avoids PermissionError: [WinError 32]) if logging_file_path: f_handler.close() logger.removeHandler(f_handler) raise _ProcessingError( "Error while processing function {}:\n {}".format( processor.name, str(e) ) ) from e # Close the file handler (this avoids PermissionError: [WinError 32]) if logging_file_path: f_handler.close() logger.removeHandler(f_handler) if not return_all_series: # Return just the output series output_dict = {key: series_dict[str(key)] for key in output_keys} series_dict = output_dict if drop_keys is not None: # Drop the keys that should not be included in the output output_dict = { key: series_dict[key] for key in set(series_dict.keys()).difference(drop_keys) } series_dict = output_dict if return_df: # We merge the series dict into a DataFrame return series_dict_to_df(series_dict) else: return [s for s in series_dict.values()] def serialize(self, file_path: Union[str, Path]) -> None: """Serialize this ``SeriesPipeline`` instance. Notes ------ As we use [Dill](https://github.com/uqfoundation/dill){:target="_blank"} to serialize, we can also serialize (decorator)functions which are defined in the local scope, like lambdas. Parameters ---------- file_path : Union[str, Path] The path where the ``SeriesProcessor`` will be serialized. """ with open(file_path, "wb") as f: dill.dump(self, f, recurse=True) def __repr__(self) -> str: """Return formal representation of object.""" return "[\n" + "".join([f"\t{str(p)}\n" for p in self.processing_steps]) + "]" def __str__(self) -> str: """Return informal representation of object.""" return self.__repr__()Pipeline for applying
SeriesProcessorobjects sequentially.Parameters
processors:List[Union[SeriesProcessor, SeriesPipeline]], optional- List of
SeriesProcessororSeriesPipelineinstances that will be applied sequentially to the internal series dict, by default None. The processing steps will be executed in the same order as passed in this list.
Methods
def get_required_series(self)-
Expand source code
def get_required_series(self) -> List[str]: """Return all required series names for this pipeline. Return the list of series names that are required in order to execute all the ``SeriesProcessor`` objects of this processing pipeline. Returns ------- List[str] List of all the required series names. """ return list( set(flatten(step.get_required_series() for step in self.processing_steps)) )Return all required series names for this pipeline.
Return the list of series names that are required in order to execute all the
SeriesProcessorobjects of this processing pipeline.Returns
List[str]- List of all the required series names.
def append(self, processor)-
Expand source code
def append(self, processor: Union[SeriesProcessor, SeriesPipeline]) -> None: """Append a ``SeriesProcessor`` at the end of the pipeline. Parameters ---------- processor : Union[SeriesProcessor, SeriesPipeline] The ``SeriesProcessor`` or ``SeriesPipeline`` that will be added to the end of the pipeline. """ if isinstance(processor, SeriesProcessor): self.processing_steps.append(processor) elif isinstance(processor, SeriesPipeline): self.processing_steps.extend(processor.processing_steps) else: raise TypeError( "Can only append SeriesProcessor or SeriesPipeline, " + f"not {type(processor)}" )Append a
SeriesProcessorat the end of the pipeline.Parameters
processor:Union[SeriesProcessor, SeriesPipeline]- The
SeriesProcessororSeriesPipelinethat will be added to the end of the pipeline.
def insert(self, idx, processor)-
Expand source code
def insert( self, idx: int, processor: Union[SeriesProcessor, SeriesPipeline] ) -> None: """Insert a ``SeriesProcessor`` at the given index in the pipeline. Parameters ---------- idx : int The index where the given processor should be inserted in the pipeline. Index 0 will insert the given processor at the front of the pipeline, and index ``len(pipeline)`` is equivalent to appending the processor. processor : Union[SeriesProcessor, SeriesPipeline] The ``SeriesProcessor`` or ``SeriesPipeline`` that will be inserted.<br> .. note:: If the given processor is a ``SeriesPipeline``, all its processors will be inserted sequentially, starting from the given index. """ if isinstance(processor, SeriesProcessor): self.processing_steps.insert(idx, processor) elif isinstance(processor, SeriesPipeline): for i, ps in enumerate(processor.processing_steps): self.insert(idx + i, ps) else: raise TypeError( "Can only insert a SeriesProcessor or SeriesPipeline, " + f"not {type(processor)}" )Insert a
SeriesProcessorat the given index in the pipeline.Parameters
idx:int- The index where the given processor should be inserted in the pipeline.
Index 0 will insert the given processor at the front of the pipeline,
and index
len(pipeline)is equivalent to appending the processor. processor:Union[SeriesProcessor, SeriesPipeline]- The
SeriesProcessororSeriesPipelinethat will be inserted.Note
If the given processor is aSeriesPipeline, all its processors will be inserted sequentially, starting from the given index.
def process(self, data, return_df=False, return_all_series=True, drop_keys=None, copy=False, logging_file_path=None)-
Expand source code
def process( self, data: Union[pd.Series, pd.DataFrame, List[Union[pd.Series, pd.DataFrame]]], return_df: Optional[bool] = False, return_all_series: Optional[bool] = True, drop_keys: Optional[List[str]] = None, copy: Optional[bool] = False, logging_file_path: Optional[Union[str, Path]] = None, ) -> Union[List[pd.Series], pd.DataFrame]: """Execute all ``SeriesProcessor`` objects in pipeline sequentially. Apply all the processing steps on passed Series list or DataFrame and return the preprocessed Series list or DataFrame. Parameters ---------- data : Union[pd.Series, pd.DataFrame, List[Union[pd.Series, pd.DataFrame]]] Dataframe or Series or list thereof, with all the required data for the processing steps. \n **Remark**: each Series / DataFrame must have a ``pd.DatetimeIndex``. **Remark**: we assume that each name / column is unique. return_df : bool, optional Whether the output needs to be a series list or a DataFrame, by default False. If True the output series will be combined to a DataFrame with an outer merge. return_all_series : bool, optional Whether the output needs to return all the series, by default True. * If True the output will contain all series that were passed to this method. * If False the output will contain just the required series (see ``get_required_series``). drop_keys : List[str], optional Which keys should be dropped when returning the output, by default None. copy : bool, optional Whether the series in ``data`` should be copied, by default False. logging_file_path : Union[str, Path], optional The file path where the logged messages are stored, by default None. If ``None``, then no logging ``FileHandler`` will be used and the logging messages are only pushed to stdout. Otherwise, a logging ``FileHandler`` will write the logged messages to the given file path. Returns ------- Union[List[pd.Series], pd.DataFrame] The preprocessed series. Notes ----- * If a ``logging_file_path`` is provided, the execution (time) info can be retrieved by calling ``logger.get_processor_logs(logging_file_path)``. <br> Be aware that the ``logging_file_path`` gets cleared before the logger pushes logged messages. Hence, one should use a separate logging file for each constructed processing and feature instance with this library. * If a series processor its function output is a ``np.ndarray``, the input series dict (required dict for that function) must contain just 1 series! That series its name and index are used to return a series dict. When a user does not want a numpy array to replace its input series, it is his / her responsibility to create a new ``pd.Series`` (or ``pd.DataFrame``) of that numpy array with a different (column) name. * If ``func_output`` is a ``pd.Series``, keep in mind that the input series gets transformed (i.e., replaced) in the pipeline with the ``func_output`` when the series name is equal. Raises ------ _ProcessingError Error raised when a processing step fails. """ # Delete other logging handlers delete_logging_handlers(logger) # Add logging handler (if path provided) if logging_file_path: f_handler = add_logging_handler(logger, logging_file_path) # Convert the data to a series_dict series_dict: Dict[str, pd.Series] = {} for s in to_series_list(data): # Assert the assumptions we make! if len(s): assert isinstance(s.index, pd.DatetimeIndex) # TODO: also check monotonic increasing? if s.name in self.get_required_series(): series_dict[str(s.name)] = s.copy() if copy else s elif return_all_series: # If all the series have to be returned series_dict[str(s.name)] = s.copy() if copy else s output_keys: Set[str] = set() # Maintain set of output series for processor in self.processing_steps: try: processed_dict = processor(series_dict) output_keys.update(processed_dict.keys()) series_dict.update(processed_dict) except Exception as e: # Close the file handler (this avoids PermissionError: [WinError 32]) if logging_file_path: f_handler.close() logger.removeHandler(f_handler) raise _ProcessingError( "Error while processing function {}:\n {}".format( processor.name, str(e) ) ) from e # Close the file handler (this avoids PermissionError: [WinError 32]) if logging_file_path: f_handler.close() logger.removeHandler(f_handler) if not return_all_series: # Return just the output series output_dict = {key: series_dict[str(key)] for key in output_keys} series_dict = output_dict if drop_keys is not None: # Drop the keys that should not be included in the output output_dict = { key: series_dict[key] for key in set(series_dict.keys()).difference(drop_keys) } series_dict = output_dict if return_df: # We merge the series dict into a DataFrame return series_dict_to_df(series_dict) else: return [s for s in series_dict.values()]Execute all
SeriesProcessorobjects in pipeline sequentially.Apply all the processing steps on passed Series list or DataFrame and return the preprocessed Series list or DataFrame.
Parameters
data:Union[pd.Series, pd.DataFrame, List[Union[pd.Series, pd.DataFrame]]]-
Dataframe or Series or list thereof, with all the required data for the processing steps.
Remark: each Series / DataFrame must have a
pd.DatetimeIndex. Remark: we assume that each name / column is unique. return_df:bool, optional- Whether the output needs to be a series list or a DataFrame, by default False. If True the output series will be combined to a DataFrame with an outer merge.
return_all_series:bool, optional- Whether the output needs to return all the series, by default True.
* If True the output will contain all series that were passed to this
method.
* If False the output will contain just the required series (see
get_required_series). drop_keys:List[str], optional- Which keys should be dropped when returning the output, by default None.
copy:bool, optional- Whether the series in
datashould be copied, by default False. logging_file_path:Union[str, Path], optional- The file path where the logged messages are stored, by default None.
If
None, then no loggingFileHandlerwill be used and the logging messages are only pushed to stdout. Otherwise, a loggingFileHandlerwill write the logged messages to the given file path.
Returns
Union[List[pd.Series], pd.DataFrame]- The preprocessed series.
Notes
- If a
logging_file_pathis provided, the execution (time) info can be retrieved by callingget_processor_logs()(logging_file_path).
Be aware that thelogging_file_pathgets cleared before the logger pushes logged messages. Hence, one should use a separate logging file for each constructed processing and feature instance with this library. - If a series processor its function output is a
np.ndarray, the input series dict (required dict for that function) must contain just 1 series! That series its name and index are used to return a series dict. When a user does not want a numpy array to replace its input series, it is his / her responsibility to create a newpd.Series(orpd.DataFrame) of that numpy array with a different (column) name. - If
func_outputis apd.Series, keep in mind that the input series gets transformed (i.e., replaced) in the pipeline with thefunc_outputwhen the series name is equal.
Raises
_ProcessingError- Error raised when a processing step fails.
def serialize(self, file_path)-
Expand source code
def serialize(self, file_path: Union[str, Path]) -> None: """Serialize this ``SeriesPipeline`` instance. Notes ------ As we use [Dill](https://github.com/uqfoundation/dill){:target="_blank"} to serialize, we can also serialize (decorator)functions which are defined in the local scope, like lambdas. Parameters ---------- file_path : Union[str, Path] The path where the ``SeriesProcessor`` will be serialized. """ with open(file_path, "wb") as f: dill.dump(self, f, recurse=True)Serialize this
SeriesPipelineinstance.Notes
As we use Dill to serialize, we can also serialize (decorator)functions which are defined in the local scope, like lambdas.
Parameters
file_path:Union[str, Path]- The path where the
SeriesProcessorwill be serialized.